Overview
In part three of this series, we configure MLFlow for production by defining our tracking server as a containerized PostgreSQL database and our artifact store as containerized MinIO storage. We then integrate MLFlow into our Kedro project in order to start tracking our model development.
Introduction
In the previous post of this series, we configured the ModelBuilder class to add structure to our custom time-series model which in turn enhanced both reproducibility and scalability. In this post, we are going to transition from running our project on our local environment to running inside a containerized environment. In addition, we are going to walkthough setting up MLFlow and its necessary components as containerized services. Finally, we are going to levarge Kedro hooks to track our machine learning experiments with MLFlow.
Getting Started
First thing we need to do is to add MLFlow as a dependency to our environment.yml file. We are also going to need to install psycopg2 to allow MLFlow to interact with PostgreSQL.
Depending on what opperating system you are using you may need to install psycopg2-binary intead of psycopg2. In this post we are going to be running everything from inside containers that are running Linux. So we will be using psycopg2-binary.
name: my_environment_name
channels:
- conda-forge
- defaults
dependencies:
- 'pymc=5.20.1'
- 'graphviz=12.2.1' # New dependency
- 'numpyro=0.17.0'
- pip:
- ipython>=8.10
- jupyterlab>=3.0
- kedro-datasets>=3.0
- kedro-viz>=6.7.0
- kedro[jupyter]~=0.19.11
- notebook
- pre-commit~=3.5
- polars~=1.23.0
- pyarrow~=18.1.0
- plotly~=5.24.0
- openpyxl~=3.1.0
- kedro-docker~=0.6.2
- pymc-extras==0.2.3
- mlflow==2.19.0 # New dependency
- psycopg2-binary==2.9.10 # New dependencySetting up MLFlow
Now is a good time to transition from running our pipelines in virtual environments on our machine to running inside of containers. Let’s modify the Dockerfile that we generated in part one of this series when we introduced the kedro-docker plugin. We are going to switch from using UV and pip to manage our dependencies when building our image to using Conda.
#./Dockerfile
ARG BASE_IMAGE=python:3.9-slim
FROM $BASE_IMAGE as runtime-environment
# install base utils
RUN apt-get update \
&& apt-get install -y build-essential \
&& apt-get install -y wget \
&& apt-get install -y git \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# install miniconda
ENV CONDA_DIR /opt/conda
RUN wget --quiet https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh -O ~/miniconda.sh && \
/bin/bash ~/miniconda.sh -b -p /opt/conda
# put conda in path
ENV PATH=$CONDA_DIR/bin:$PATH
# install project requirements
COPY environment.yml /tmp/environment.yml
RUN conda env update --name base --file /tmp/environment.yml --prune
# add kedro user
ARG KEDRO_UID=999
ARG KEDRO_GID=0
RUN groupadd -f -g ${KEDRO_GID} kedro_group && \
useradd -m -d /home/kedro_docker -s /bin/bash -g ${KEDRO_GID} -u ${KEDRO_UID} kedro_docker
WORKDIR /home/kedro_docker
USER kedro_docker
FROM runtime-environment
# copy the whole project except what is in .dockerignore
ARG KEDRO_UID=999
ARG KEDRO_GID=0
COPY --chown=${KEDRO_UID}:${KEDRO_GID} . .
EXPOSE 8888
CMD ["kedro", "run"]Now that our Kedro project can run inside a container let’s configure MLFlow. We will need to configure the following:
- Define a backend store where metrics, parameters, and metadata are stored
- Define an artifact store where large files like models and figures are stored
- Define a tracking server that is listening to incoming requests
- Allow the server, storage, and our pipelines to communincate with each other
Backend Store
As we mentioned earlier, we are going to use PostgreSQL to store our metrics, parameters, and other metadata. In a docker compose file, let’s define our PostgreSQL service. You can name the service however you like; we will name it mlflow-logs. We also need to define a username, password, and database name for our service. We will name our database mlflowdb. We are going to pass in the username and password as an environment variable using secrets. For that you need to make sure you set those variables in your environment. On Linux/MacOS you can set an environment variable like so:
export POSTGRES_USER=some_user_nameOn Windows using PowerShell you can set it like this:
$env:POSTGRES_USER = "some_user_name"In addition, we need to make sure that what we log into our database persists after the container is brought down. We will define a docker volume and call it pg_mlflow_db. Our docker-compose.yml file looks like this so far:
#./docker-compose.yml
services:
mlflow-logs:
image: postgres:16.4
secrets:
- POSTGRES_USER
- POSTGRES_PASSWORD
environment:
- POSTGRES_USER_FILE=/run/secrets/POSTGRES_USER
- POSTGRES_PASSWORD_FILE=/run/secrets/POSTGRES_PASSWORD
- POSTGRES_DB=mlflowdb
ports:
- 5432:5432
volumes:
- pg_mlflow_db:/var/lib/postgresql/data
volumes:
pg_mlflow_db:
secrets:
POSTGRES_USER:
environment: POSTGRES_USER
POSTGRES_PASSWORD:
environment: POSTGRES_PASSWORDNote how we are using POSTGRES_USER_FILE instead of POSTGRES_USER. This is a convention used by many docker images for passing in secrets.
Artifact Store
We need a place to store larger file objects like our models, figures, or artifacts. For that, we are going to define another service in our docker-compose.yml that will host a MinIO S3-compatible object store. Again, we define a username and password like we did before. Let’s also define a default bucket that will be created on creation of the service where we will store our artifacts. Again, like we did for our backend store our artifact store needs a persistant volume. So far we have:
#./docker-compose.yml
services:
mlflow-logs:
image: postgres:16.4
secrets:
- POSTGRES_USER
- POSTGRES_PASSWORD
environment:
- POSTGRES_USER_FILE=/run/secrets/POSTGRES_USER
- POSTGRES_PASSWORD_FILE=/run/secrets/POSTGRES_PASSWORD
- POSTGRES_DB=mlflowdb
ports:
- 5432:5432
volumes:
- pg_mlflow_db:/var/lib/postgresql/data
# New MinIO service
minio:
container_name: minio
image: 'bitnami/minio:latest'
ports:
- '9000:9000'
- '9001:9001'
secrets:
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
environment:
- MINIO_ROOT_USER_FILE=/run/secrets/AWS_ACCESS_KEY_ID
- MINIO_ROOT_PASSWORD_FILE=/run/secrets/AWS_SECRET_ACCESS_KEY
- MINIO_DEFAULT_BUCKETS=mlflow
volumes:
- minio_data:/bitnami/minio/data
volumes:
pg_mlflow_db:
minio_data:
secrets:
AWS_ACCESS_KEY_ID:
environment: AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY:
environment: AWS_SECRET_ACCESS_KEY
POSTGRES_USER:
environment: POSTGRES_USER
POSTGRES_PASSWORD:
environment: POSTGRES_PASSWORDTracking Server
We are now ready to define the MLFlow tracking-server and configure it so that it can communicate with our backend store and artifact store. The key here is to define the proper environment variables:
- MLFLOW_BACKEND_STORE_URI: This will point to our PostgreSQL service which has the form
postgresql://username:password@service_name:port/database_name - MLFLOW_ARTIFACTS_DESTINATION: This will point to our storage bucket which has the form
s3://bucket_name - MLFLOW_S3_ENDPOINT_URL: This will point to our MinIO service and which the form
http://service_name:port - AWS_ACCESS_KEY_ID: This is the access key ID to our MinIO service. It can be the root user (not recommended) or bucket specific access key
- AWS_SECRET_ACCESS_KEY: This is the secret access key ID to our MinIO service. It can be the root password (not recommended) or bucket specific secret access key
Let’s go ahead and add our tracking-server service to our compose file:
#./docker-compose.yml
services:
mlflow-logs:
image: postgres:16.4
secrets:
- POSTGRES_USER
- POSTGRES_PASSWORD
environment:
- POSTGRES_USER_FILE=/run/secrets/POSTGRES_USER
- POSTGRES_PASSWORD_FILE=/run/secrets/POSTGRES_PASSWORD
- POSTGRES_DB=mlflowdb
ports:
- 5432:5432
volumes:
- pg_mlflow_db:/var/lib/postgresql/data
minio:
container_name: minio
image: 'bitnami/minio:latest'
ports:
- '9000:9000'
- '9001:9001'
secrets:
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
environment:
- MINIO_ROOT_USER_FILE=/run/secrets/AWS_ACCESS_KEY_ID
- MINIO_ROOT_PASSWORD_FILE=/run/secrets/AWS_SECRET_ACCESS_KEY
- MINIO_DEFAULT_BUCKETS=mlflow
volumes:
- minio_data:/bitnami/minio/data
# new tracking server service
mlflow-tracking-server:
image: ghcr.io/mlflow/mlflow:v2.19.0
command: >
bash -c "
pip install -U pip
pip install psycopg2-binary boto3
mlflow server --host 0.0.0.0 --port 5000 --workers 1
"
ports:
- 5050:5000
environment:
- MLFLOW_BACKEND_STORE_URI=postgresql://${POSTGRES_USER}:${POSTGRES_PASSWORD}@mlflow-logs:5432/mlflowdb
- MLFLOW_ARTIFACTS_DESTINATION=s3://mlflow
- MLFLOW_S3_ENDPOINT_URL=http://minio:9000
- MLFLOW_S3_IGNORE_TLS=true
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
depends_on:
- minio
- mlflow-logs
stop_grace_period: 1s
volumes:
pg_mlflow_db:
minio_data:
secrets:
AWS_ACCESS_KEY_ID:
environment: AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY:
environment: AWS_SECRET_ACCESS_KEY
POSTGRES_USER:
environment: POSTGRES_USER
POSTGRES_PASSWORD:
environment: POSTGRES_PASSWORDEnvironment variables that aren’t passed in using the /run/secrets method can be viewed by echoing that variable in the container’s shell!
Kedro Project Image
The final service we will be adding in this section is the image of our Kedro project. We set a profile of manual on this service so that the container isn’t brought up automatically. We do this because it is likely that you want this service to run on a schedule so we just let the scheduler handle bringing the service up. Notice that we set the environment variable MLFLOW_TRACKING_URI to the service name and port that is running our MLFlow tracking server. This will allow us to communicate from our Kedro project service.
#./docker-compose.yml
services:
mlflow-logs:
image: postgres:16.4
secrets:
- POSTGRES_USER
- POSTGRES_PASSWORD
environment:
- POSTGRES_USER_FILE=/run/secrets/POSTGRES_USER
- POSTGRES_PASSWORD_FILE=/run/secrets/POSTGRES_PASSWORD
- POSTGRES_DB=mlflowdb
ports:
- 5432:5432
volumes:
- pg_mlflow_db:/var/lib/postgresql/data
minio:
container_name: minio
image: 'bitnami/minio:latest'
ports:
- '9000:9000'
- '9001:9001'
secrets:
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
environment:
- MINIO_ROOT_USER_FILE=/run/secrets/AWS_ACCESS_KEY_ID
- MINIO_ROOT_PASSWORD_FILE=/run/secrets/AWS_SECRET_ACCESS_KEY
- MINIO_DEFAULT_BUCKETS=mlflow
volumes:
- minio_data:/bitnami/minio/data
mlflow-tracking-server:
image: ghcr.io/mlflow/mlflow:v2.19.0
command: >
bash -c "
pip install -U pip
pip install psycopg2-binary boto3
mlflow server --host 0.0.0.0 --port 5000 --workers 1
"
ports:
- 5050:5000
environment:
- MLFLOW_BACKEND_STORE_URI=postgresql://${POSTGRES_USER}:${POSTGRES_PASSWORD}@mlflow-logs:5432/mlflowdb
- MLFLOW_ARTIFACTS_DESTINATION=s3://mlflow
- MLFLOW_S3_ENDPOINT_URL=http://minio:9000
- MLFLOW_S3_IGNORE_TLS=true
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
depends_on:
- minio
- mlflow-logs
stop_grace_period: 1s
# New service added
climate-brazil:
profiles:
- manual
build: .
environment:
- MLFLOW_TRACKING_URI=http://mlflow-tracking-server:5000
depends_on:
- mlflow-tracking-server
- minio
- mlflow-logs
volumes:
pg_mlflow_db:
minio_data:
secrets:
AWS_ACCESS_KEY_ID:
environment: AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY:
environment: AWS_SECRET_ACCESS_KEY
POSTGRES_USER:
environment: POSTGRES_USER
POSTGRES_PASSWORD:
environment: POSTGRES_PASSWORDIntegrating MLFlow
Now that we have our services defined we need to modify our Kedro project to interact with the MLFlow tracking server. For that we are going to introduce hooks; another useful Kedro feature.
Kedro Hooks
Hooks are a great way to add additional functionality to your pipelines at specific points during, before or after execution. Common use cases of hooks are:
- Injecting additional logging behavior before/after pipeline/node execution
- Validating input data is in the correct format before executing a node
- Debugging a node/pipeline
- Tracking/Profiling resource utilization
- Customizing load and save methods
We are going to use hooks to inject additional logging and customize saving methods by logging metrics and parameters, and saving models/artifacts using MLFlow.
To define hooks in Kedro we need to create a new file hooks.py inside of /src/climate_brazil/ and create a class that will contain our hook’s logic as it’s methods. The scaffolding will look like this:
# /src/climate_brazil/hooks.py
from typing import Any
from kedro.framework.hooks import hook_impl
class ModelTrackingHooks:
def __init__(self):
pass
@hook_impl
def after_node_run(
self, node: Node, outputs: dict[str, Any], inputs: dict[str, Any]
) -> None:
pass
@hook_impl
def after_pipeline_run(self) -> None:
passA lot of times you don’t actually need to define a __init__() method for you hook class. We will define it in our use case so that we can initialize MLFlow.
Configure MLFlow
Before we start experiment tracking with MLFlow, let’s set up some configuration variables inside of conf/base/parameters_ML.yml. First, let’s have the option to either use or not use MLFlow. Second, artifact logging can use up quite a bit of storage, so let’s make that optional as well. Finally, let’s set an experiment name and tags that will help differentiate experiment runs.
#conf/base/parameters_ML.yml
mlflow_config:
use_mlflow: true
log_artifacts: true
experiment_name: climate-brazil
tags:
model: structural time-series
trend_component: Gaussian Process
seasonal_component: FourierInitialize MLFlow
Now we need to initialze MLFlow whenever we start a run of our pipeline. As a reminder we are going to do that using the Kedro hook we defined scaffolding for earlier.
# /src/climate_brazil/hooks.py
from typing import Any
from kedro.framework.hooks import hook_impl
class ModelTrackingHooks:
def __init__(self):
1 self.run_ids = {}
2 conf_path = "./conf"
conf_loader = OmegaConfigLoader(conf_source=conf_path)
self.params = conf_loader.get('parameters')
3 if self.params['mlflow_config']['use_mlflow']:
# set the experiment and start an MLFlow run
mlflow.set_experiment(
experiment_name=self.params['mlflow_config']['experiment_name']
)
mlflow.start_run()
# Save the run ID so that we can nest in the individual city models
4 self.run_ids["parent_run_id"] = mlflow.active_run().info.run_id
# If you have tags set for the run set them in MLFlow
5 if self.params['mlflow_config']['tags']:
mlflow.set_tags(self.params['mlflow_config']['tags'])- 1
- Initialize a dictionary to store run IDs
- 2
- Load configurations we defined from inside our parameters files
- 3
-
If we are using
MLFlowset the experiment name we defined and start a run - 4
- Store the run ID inside the dictionary object we initialized earlier
- 5
- If tags are defined set them to the current run
You can click on the above circled numbers to highlight the corresponding lines in the code cell directly above them.
Tracking Prior & Sampler Configurations
As soon as we start an MLFlow run we can start logging the parameters for our priors and our sampler configurations that we defined in /conf/base/parameters_ML.yml. Let’s go ahead and log those with MLFlow inside our __init__() method:
# /src/climate_brazil/hooks.py
from typing import Any
import mlflow
from kedro.framework.hooks import hook_impl
class ModelTrackingHooks:
def __init__(self):
self.run_ids = {}
conf_path = "./conf"
conf_loader = OmegaConfigLoader(conf_source=conf_path)
self.params = conf_loader.get('parameters')
if self.params['mlflow_config']['use_mlflow']:
# set the experiment and start an MLFlow run
mlflow.set_experiment(
experiment_name=self.params['mlflow_config']['experiment_name']
)
mlflow.start_run()
# Save the run ID so that we can nest in the individual city models
self.run_ids["parent_run_id"] = mlflow.active_run().info.run_id
# We can log our model and sampler configs early
1 mlflow.log_params(self.params['model_config'])
2 mlflow.log_params(self.params['sampler_config'])
# If you have tags set for the run set them in MLFlow
if self.params['mlflow_config']['tags']:
mlflow.set_tags(self.params['mlflow_config']['tags'])- 1
- We log our model configuration, which if you recall, holds the parameters for our priors
- 2
- Here we log our sampler configurations. This is useful to log for when we have divergences, our sampling is slow, or when our effective sampling size is too small.
Tracking Model Specifications
PyMC allows you to plot a graphical representation of the model using GraphViz. These plots can facilitate comparing different model specifications across experiment runs without needing to read through code. So, we will generate these figures and log them as artifacts. It’s also a good idea to define one run of our experiment as running through all of the cities. So, we will create nested runs for each city within our top-level parent run.
# /src/climate_brazil/hooks.py
from typing import Any
import mlflow
from kedro.framework.hooks import hook_impl
cities = [
"Belem", "Curitiba", "Fortaleza", "Goiania", "Macapa", "Manaus",
"Recife", "Rio", "Salvador", "Sao_Luiz", "Sao_Paulo", "Vitoria"
]
class ModelTrackingHooks:
def __init__(self):
self.run_ids = {}
conf_path = "./conf"
conf_loader = OmegaConfigLoader(conf_source=conf_path)
self.params = conf_loader.get('parameters')
if self.params['mlflow_config']['use_mlflow']:
# set the experiment and start an MLFlow run
mlflow.set_experiment(
experiment_name=self.params['mlflow_config']['experiment_name']
)
mlflow.start_run()
# Save the run ID so that we can nest in the individual city models
self.run_ids["parent_run_id"] = mlflow.active_run().info.run_id
# We can log our model and sampler configs early
mlflow.log_params(self.params['model_config'])
mlflow.log_params(self.params['sampler_config'])
# If you have tags set for the run set them in MLFlow
if self.params['mlflow_config']['tags']:
mlflow.set_tags(self.params['mlflow_config']['tags'])
1 @hook_impl
def after_node_run(
self, node: Node, outputs: dict[str, Any], inputs: dict[str, Any]
) -> None:
"""
Here we are going to pull outputs from specific nodes and log them with MLFlow
---
Params:
node: Attributes of the node that just ran
outputs: Outputs of the node that just ran
inputes: Inputes of the node that just ran
"""
2 if node.name == "train":
3 for city in cities:
if self.params['mlflow_config']['use_mlflow']:
# Start a nested run
4 mlflow.start_run(
run_name=city,
nested=True,
parent_run_id=self.run_ids['parent_run_id']
)
# Store city specific run ids for later
5 self.run_ids[f"{city}_run_id"] = mlflow.active_run().info.run_id
# If you want to log artifacts log them here
6 if self.params['mlflow_config']['log_artifacts']:
local_path = f"./data/08_reporting/{city}_model_graph.png"
outputs[f"{city}_model"].model.to_graphviz(
save=local_path,
figsize=(12,8)
)
# log graph representation of model
mlflow.log_artifact(local_path=local_path, artifact_path="figures")
# Define the inputs the model expects when forecasting
7 mlflow.end_run()- 1
-
Define a hook that will run after a
Kedronode completes execution. - 2
-
If the node that completes is named
trainthen fire the hook. - 3
- For each city prepare to log city specific attributes.
- 4
- Start a nested run within our current active run.
- 5
- Store the nested run ID.
- 6
-
Create the graphical representation of the model and log it as an artifact in our artifact store under the directory of
figures/ - 7
- Close the active nested run.
Logging Divergences and Infrence Data Attributes
It is also useful to log any divergences you come across during sampling because as you fit more and more models it can be difficult to keep track of any sampling problems. We will also log our Inference Data attributes which will include the model ID that ModelBuilder gives a new instance of our model, the city name, and the mean and standard deviation of our average temperatures for each city.
# /src/climate_brazil/hooks.py
from typing import Any
import mlflow
from kedro.framework.hooks import hook_impl
cities = [
"Belem", "Curitiba", "Fortaleza", "Goiania", "Macapa", "Manaus",
"Recife", "Rio", "Salvador", "Sao_Luiz", "Sao_Paulo", "Vitoria"
]
class ModelTrackingHooks:
def __init__(self):
self.run_ids = {}
conf_path = "./conf"
conf_loader = OmegaConfigLoader(conf_source=conf_path)
self.params = conf_loader.get('parameters')
if self.params['mlflow_config']['use_mlflow']:
# set the experiment and start an MLFlow run
mlflow.set_experiment(
experiment_name=self.params['mlflow_config']['experiment_name']
)
mlflow.start_run()
# Save the run ID so that we can nest in the individual city models
self.run_ids["parent_run_id"] = mlflow.active_run().info.run_id
# We can log our model and sampler configs early
mlflow.log_params(self.params['model_config'])
mlflow.log_params(self.params['sampler_config'])
# If you have tags set for the run set them in MLFlow
if self.params['mlflow_config']['tags']:
mlflow.set_tags(self.params['mlflow_config']['tags'])
@hook_impl
def after_node_run(
self, node: Node, outputs: dict[str, Any], inputs: dict[str, Any]
) -> None:
"""
Here we are going to pull outputs from specific nodes and log them with MLFlow
---
Params:
node: Attributes of the node that just ran
outputs: Outputs of the node that just ran
inputes: Inputes of the node that just ran
"""
if node.name == "train":
for city in cities:
if self.params['mlflow_config']['use_mlflow']:
# Start a nested run
mlflow.start_run(
run_name=city,
nested=True,
parent_run_id=self.run_ids['parent_run_id']
)
# Store city specific run ids for later
self.run_ids[f"{city}_run_id"] = mlflow.active_run().info.run_id
# If you want to log artifacts log them here
if self.params['mlflow_config']['log_artifacts']:
local_path = f"./data/08_reporting/{city}_model_graph.png"
outputs[f"{city}_model"].model.to_graphviz(
save=local_path,
figsize=(12,8)
)
# log graph representation of model
mlflow.log_artifact(local_path=local_path, artifact_path="figures")
# log divergences and inference data attributes
1 mlflow.log_param(
"divergences",
(
outputs[f"{city}_model"]
.idata.sample_stats.diverging.sum()
.values.item()
)
)
2 mlflow.log_params(outputs[f"{city}_model"].idata.attrs)
mlflow.end_run()- 1
- Log divergences if any occured during sampling.
- 2
- Log Inference Data attributes.
Logging Metrics
Obviously, we would want to log some metrics that give us an indication of how well our model is performing. In the previous post, we decided to evaluate our model using the root mean square error (RMSE) and the 80% Highest Density Interval (HDI) coverage. Let’s go ahead and log those metrics.
# /src/climate_brazil/hooks.py
from typing import Any
import mlflow
from kedro.framework.hooks import hook_impl
cities = [
"Belem", "Curitiba", "Fortaleza", "Goiania", "Macapa", "Manaus",
"Recife", "Rio", "Salvador", "Sao_Luiz", "Sao_Paulo", "Vitoria"
]
class ModelTrackingHooks:
def __init__(self):
self.run_ids = {}
conf_path = "./conf"
conf_loader = OmegaConfigLoader(conf_source=conf_path)
self.params = conf_loader.get('parameters')
if self.params['mlflow_config']['use_mlflow']:
# set the experiment and start an MLFlow run
mlflow.set_experiment(
experiment_name=self.params['mlflow_config']['experiment_name']
)
mlflow.start_run()
# Save the run ID so that we can nest in the individual city models
self.run_ids["parent_run_id"] = mlflow.active_run().info.run_id
# We can log our model and sampler configs early
mlflow.log_params(self.params['model_config'])
mlflow.log_params(self.params['sampler_config'])
# If you have tags set for the run set them in MLFlow
if self.params['mlflow_config']['tags']:
mlflow.set_tags(self.params['mlflow_config']['tags'])
@hook_impl
def after_node_run(
self, node: Node, outputs: dict[str, Any], inputs: dict[str, Any]
) -> None:
"""
Here we are going to pull outputs from specific nodes and log them with MLFlow
---
Params:
node: Attributes of the node that just ran
outputs: Outputs of the node that just ran
inputes: Inputes of the node that just ran
"""
if node.name == "train":
for city in cities:
if self.params['mlflow_config']['use_mlflow']:
# Start a nested run
mlflow.start_run(
run_name=city,
nested=True,
parent_run_id=self.run_ids['parent_run_id']
)
# Store city specific run ids for later
self.run_ids[f"{city}_run_id"] = mlflow.active_run().info.run_id
# If you want to log artifacts log them here
if self.params['mlflow_config']['log_artifacts']:
local_path = f"./data/08_reporting/{city}_model_graph.png"
outputs[f"{city}_model"].model.to_graphviz(
save=local_path,
figsize=(12,8)
)
# log graph representation of model
mlflow.log_artifact(local_path=local_path, artifact_path="figures")
# log divergences and inference data attributes
mlflow.log_param(
"divergences",
(
outputs[f"{city}_model"]
.idata.sample_stats.diverging.sum()
.values.item()
)
)
mlflow.log_params(outputs[f"{city}_model"].idata.attrs)
mlflow.end_run()
1 if node.name in [f"{city}_forecasts_evaluation" for city in cities]:
2 city = re.search(r"(.*)(?=_forecasts_evaluation)", node.name).group(1)
if self.params['mlflow_config']['use_mlflow']:
# start up again our city specific runs to log metrics
3 mlflow.start_run(
run_id=self.run_ids[f"{city}_run_id"],
run_name=city,
nested=True,
parent_run_id=self.run_ids['parent_run_id']
)
4 mlflow.log_metrics(outputs[f'{city}_evaluation'])
5 mlflow.end_run()- 1
- Execute the hook only if the node corresponds to our evaluation nodes.
- 2
- Grab the city name using Regex.
- 3
- Re-activate the nested run corresponding to the city.
- 4
- Log the RMSE and coverage metrics
- 5
- Close the nested city run again.
Saving a Custom MLFlow Model
MLFlow has several flavors of model frameworks already built-in that allow you to save your trained model into an easily deployable MLFlow model object. Behind the scenes MLFlow defines how the model should be loaded and how predictions are to be made using the model. Since we have built a custom solution using the Probabilistic Programming Language (PPL) PyMC we need to tell MLFlow how to load and use our model during forecasting time.
# src/climate_brazil/pipelines/ML/mlflow_model_wrapper.py
import json
from mlflow.pyfunc import Context, PythonModel
from kedro_framework.pipelines.ML.ts_model import TSModel
class PyMCModelWrapper(PythonModel):
1 def load_context(self, context: Context) -> None:
"""
Loads the trained model from the given context.
---
Params:
context: The context object containing artifacts, including the model.
"""
self.model = TSModel.load(context.artifacts['model'])
2 def predict(self, context: Context, n_ahead: int) -> str:
"""
Makes predictions using the model for the specified number of time steps ahead.
---
Params:
context: The context object containing artifacts, including the model.
n_ahead: The number of future time steps to predict.
"""
preds_normalized = self.model.sample_posterior_predictive(
n_ahead=n_ahead.iloc[:, 0].values.item(),
extend_idata=False,
combined=False
)
preds = preds_normalized * self.model.idata.attrs['y_std'] +
self.model.idata.attrs['y_mean']
preds = preds.rename_vars(
{"temperature_normalized_fut": "temperature_fut"}
)
return json.dumps(preds.to_dataframe().reset_index().to_dict('records'))- 1
- Load the trained model
- 2
- Generate forecasts using the trained model
Now that we can log our model with MLFlow let’s add that logic to our hook:
# /src/climate_brazil/hooks.py
from typing import Any
import mlflow
from kedro.framework.hooks import hook_impl
cities = [
"Belem", "Curitiba", "Fortaleza", "Goiania", "Macapa", "Manaus",
"Recife", "Rio", "Salvador", "Sao_Luiz", "Sao_Paulo", "Vitoria"
]
class ModelTrackingHooks:
def __init__(self):
self.run_ids = {}
conf_path = "./conf"
conf_loader = OmegaConfigLoader(conf_source=conf_path)
self.params = conf_loader.get('parameters')
if self.params['mlflow_config']['use_mlflow']:
# set the experiment and start an MLFlow run
mlflow.set_experiment(
experiment_name=self.params['mlflow_config']['experiment_name']
)
mlflow.start_run()
# Save the run ID so that we can nest in the individual city models
self.run_ids["parent_run_id"] = mlflow.active_run().info.run_id
# We can log our model and sampler configs early
mlflow.log_params(self.params['model_config'])
mlflow.log_params(self.params['sampler_config'])
# If you have tags set for the run set them in MLFlow
if self.params['mlflow_config']['tags']:
mlflow.set_tags(self.params['mlflow_config']['tags'])
@hook_impl
def after_node_run(
self, node: Node, outputs: dict[str, Any], inputs: dict[str, Any]
) -> None:
"""
Here we are going to pull outputs from specific nodes and log them with MLFlow
---
Params:
node: Attributes of the node that just ran
outputs: Outputs of the node that just ran
inputes: Inputes of the node that just ran
"""
if node.name == "train":
for city in cities:
if self.params['mlflow_config']['use_mlflow']:
# Start a nested run
mlflow.start_run(
run_name=city,
nested=True,
parent_run_id=self.run_ids['parent_run_id']
)
# Store city specific run ids for later
self.run_ids[f"{city}_run_id"] = mlflow.active_run().info.run_id
# If you want to log artifacts log them here
if self.params['mlflow_config']['log_artifacts']:
local_path = f"./data/08_reporting/{city}_model_graph.png"
outputs[f"{city}_model"].model.to_graphviz(
save=local_path,
figsize=(12,8)
)
# log graph representation of model
mlflow.log_artifact(local_path=local_path, artifact_path="figures")
# Define the inputs the model expects when forecasting
1 input_schema = mlflow.types.Schema(
[
mlflow.types.ColSpec(
name="n_ahead",
type=mlflow.types.DataType.integer
),
]
)
# Log the model
2 with tempfile.TemporaryDirectory() as tmpdir:
file_path = os.path.join(tmpdir, f"{city}_model.nc")
outputs[f"{city}_model"].save(file_path)
mlflow.pyfunc.log_model(
artifact_path="model",
python_model=PyMCModelWrapper(),
artifacts={"model": file_path},
signature=ModelSignature(inputs=input_schema),
conda_env="./environment.yml"
)
# log divergences and inference data attributes
mlflow.log_param(
"divergences",
(
outputs[f"{city}_model"]
.idata.sample_stats.diverging.sum()
.values.item()
)
)
mlflow.log_params(outputs[f"{city}_model"].idata.attrs)
mlflow.end_run()
if node.name in [f"{city}_forecasts_evaluation" for city in cities]:
city = re.search(r"(.*)(?=_forecasts_evaluation)", node.name).group(1)
if self.params['mlflow_config']['use_mlflow']:
# start up again our city specific runs to log metrics
mlflow.start_run(
run_id=self.run_ids[f"{city}_run_id"],
run_name=city,
nested=True,
parent_run_id=self.run_ids['parent_run_id']
)
mlflow.log_metrics(outputs[f'{city}_evaluation'])
mlflow.end_run()
3 @hook_impl
def after_pipeline_run(self) -> None:
"""Hook implementation to end the MLflow run
after the Kedro pipeline finishes.
"""
if mlflow.active_run():
mlflow.end_run()- 1
- Define the input schema that our model will expect during forecasting
- 2
-
Log the model under
/modelwith the defined input schema and dependency requirements defined withinenvironment.yml - 3
-
After the pipeline executes close the
MLFlowactive run
Experiment Run
Now that we have defined our MLFlow hook, we are ready to run an experiment! Before that though, we need to activate the hook we defined.
Activating Hooks
It is quite simple to activate a Kedro hook. We just need to import our hook class into /src/climate_brazil/settings.py and add the to the file the line:
# /src/climate_brazil/settings.py
# Hooks are executed in a Last-In-First-Out (LIFO) order.
from climate_brazil.hooks import ModelTrackingHooks
HOOKS = (ModelTrackingHooks(),)Executing our pipeline
Okay, it is showtime! Let’s re-build our pipeline image and run our pipeline.
docker compose build climate-brazil
docker compose up -d
docker compose up -d climate-brazilRemember that our pipeline service has a profile set to manual. We need to explicitly bring up the service.
If you checkout the MLFlow User Interface (UI) running on localhost:5050, you should see something like this:
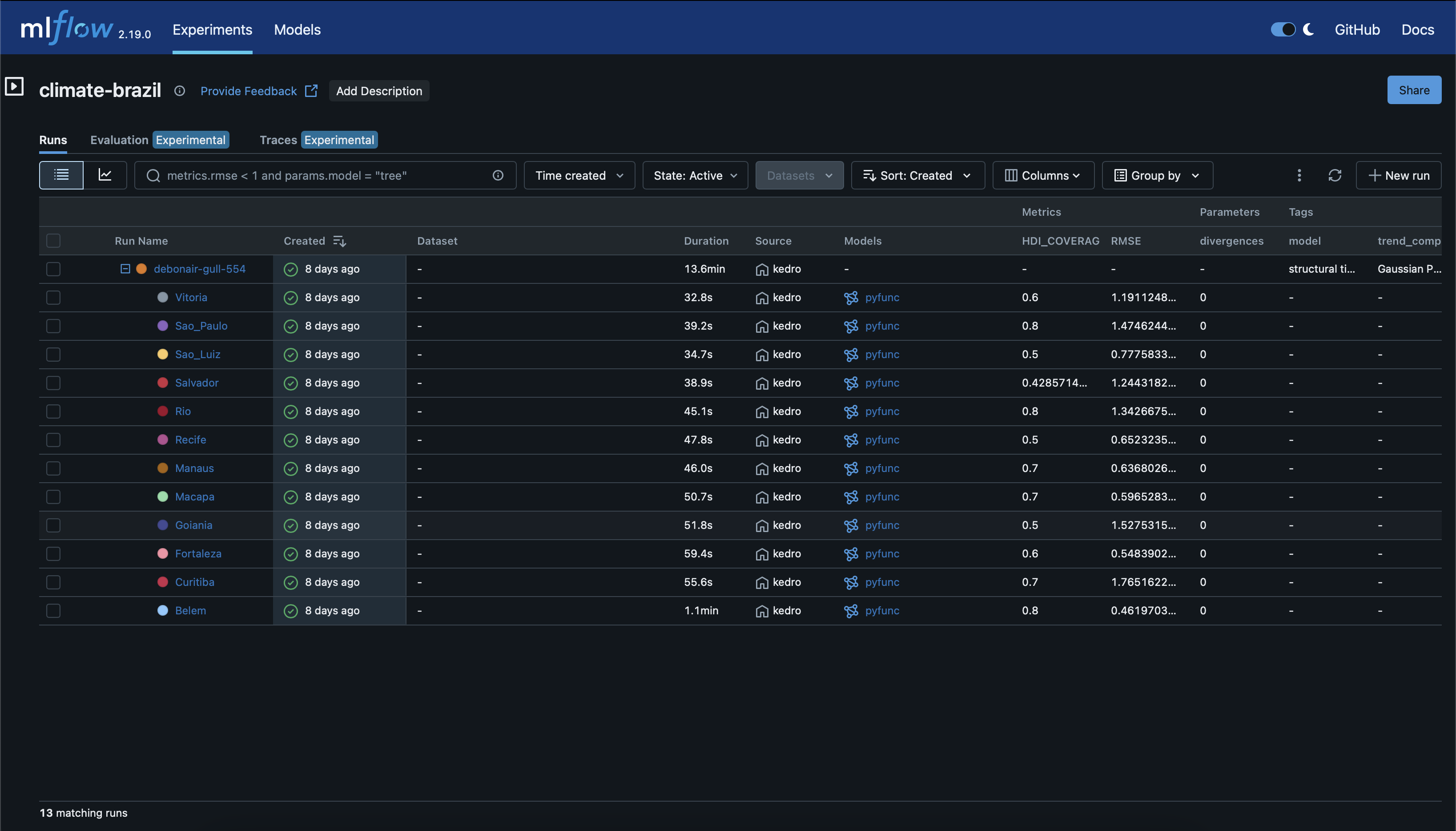
Parameters & Metrics
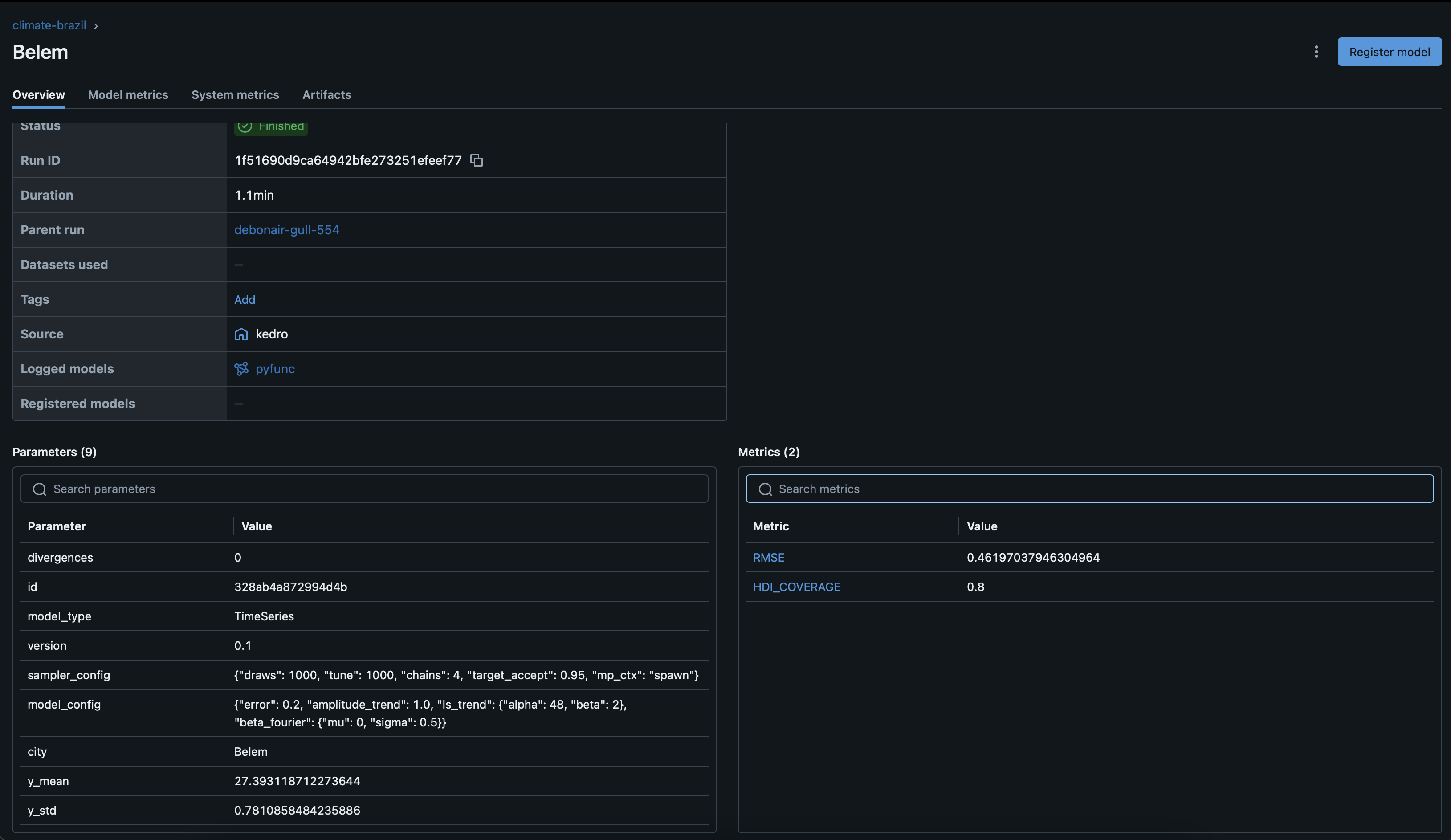
We can see more details about our nested runs by clicking on them in the UI. Here you can see both the parameters and metrics that we logged for the Brazilian city Belem.
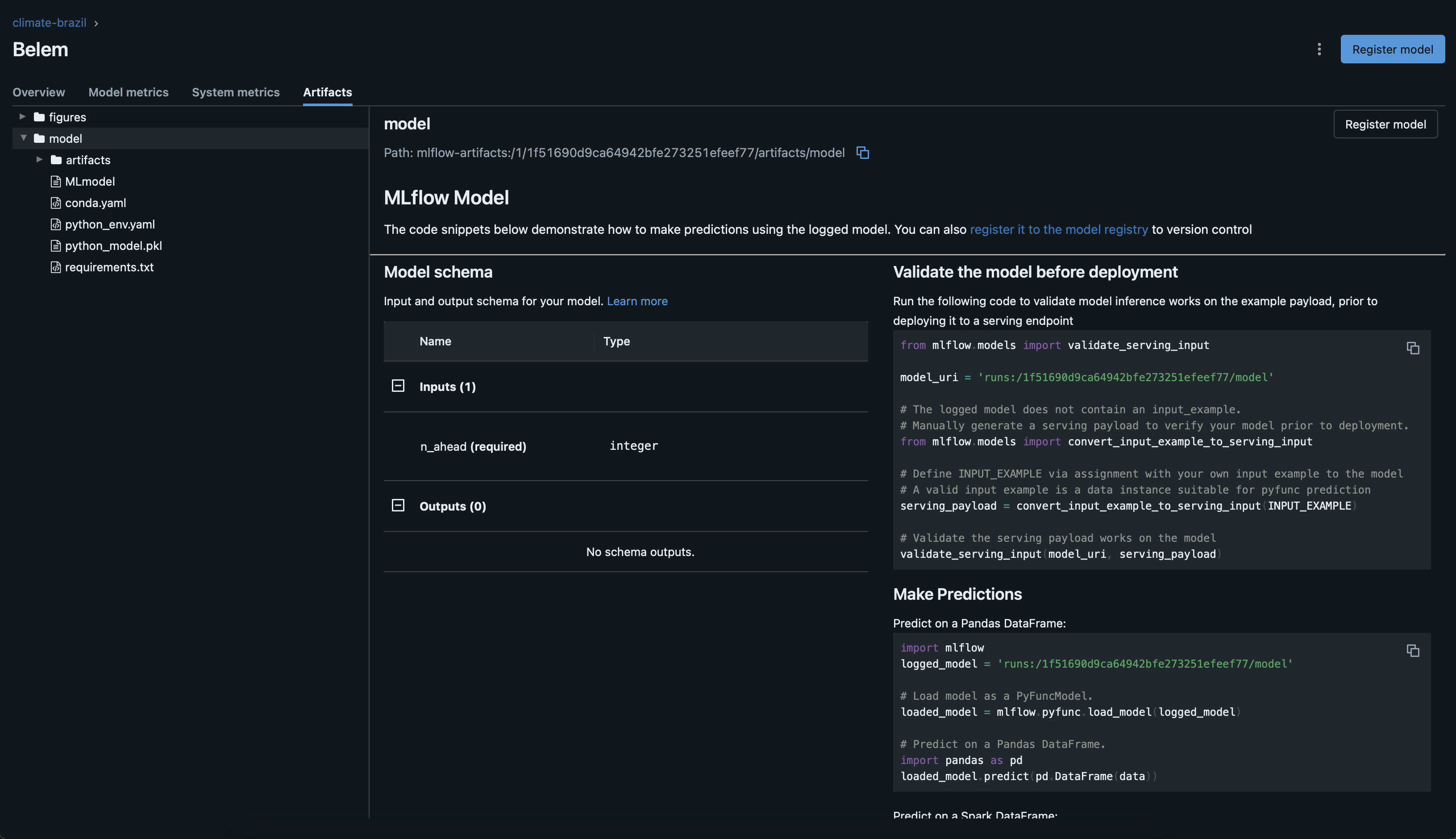
Artifacts
Finally, navigating to the artifacts tab in the UI we see the logged model, under /model, along with the expected input and some sample code to validate it produces the expected output.
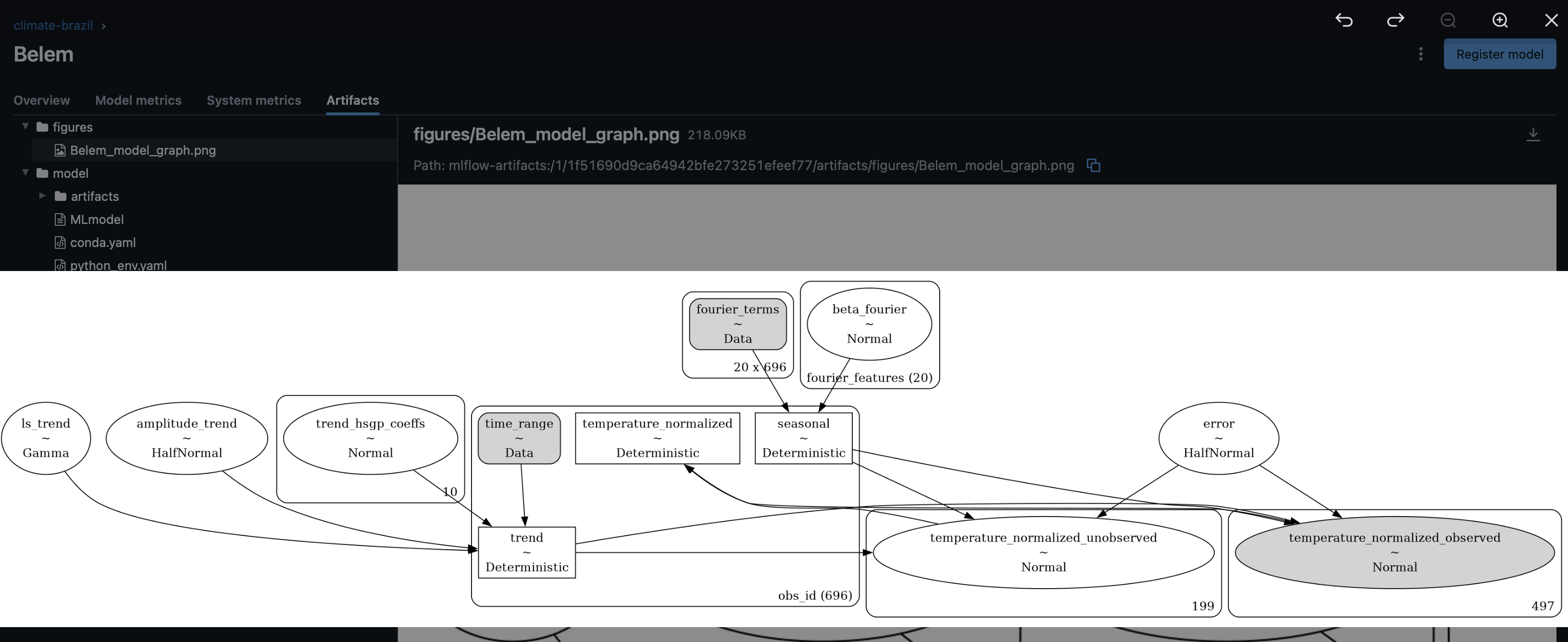
Under the /figures path, we can find the model graph figure that we logged.
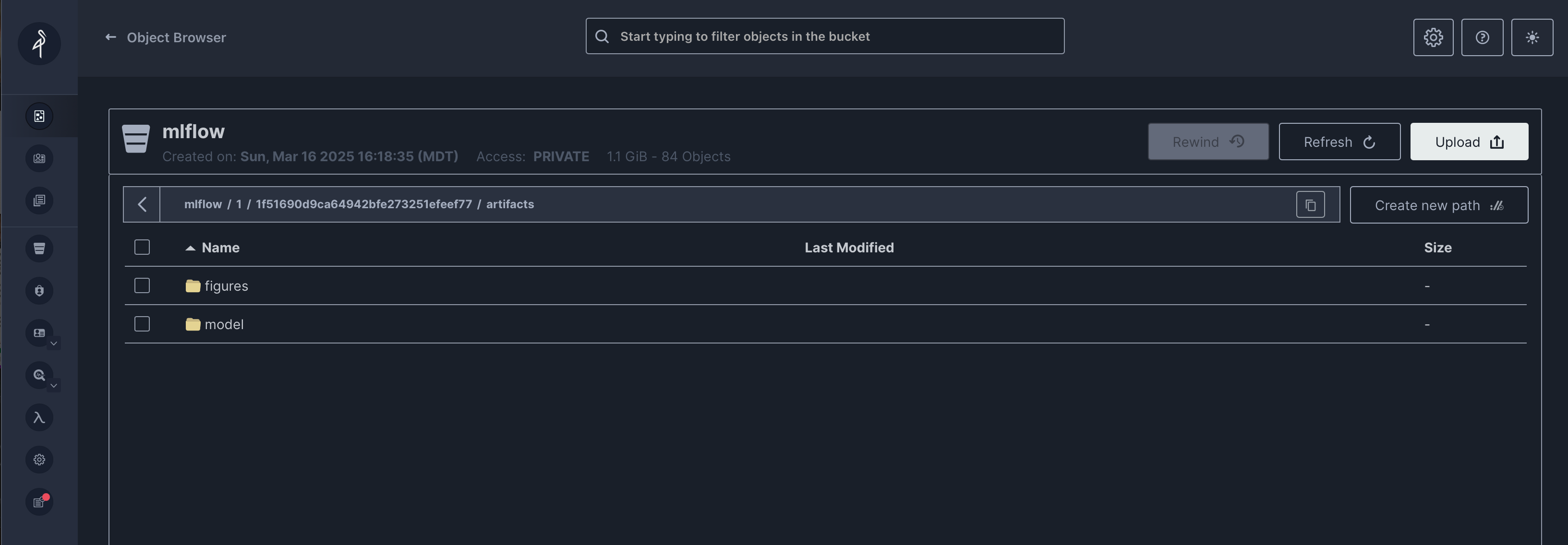
The artifacts are visible/accesible via the MLFlow UI, but remember that these objects are stored in our MinIO service. You can access the storage directly on localhost:9001 and locate the objects in our default bucket:
Summary
In this post we walked through:
- Setting up
MLFlowcomponents as containerized services - Using
Kedrohooks to inject additional functionality to our pipelines - Logging important metrics, parameters and artifacts with
MLFlow - Logging a custom model as an
MLFlowmodel
Coming Next
Right now, we are training our models sequentially in a loop. This is not feesible when you have tens of thousands of cities. In the final post of this series, we will walkthrough scaling our training with Ray.